Chorus One is now a part of Bitwise. Bitwise is a global, crypto-first asset manager with $11 billion+ in client assets and a diverse suite of investment solutions. Learn more about how Chorus One is growing as a part of Bitwise at onchain.bitwiseinvestments.com.
Timing Games on Solana: Validator Incentives, Network Impacts, and Agave's Hidden Inefficiencies
Our team at Chorus One has been closely following the recent discussions around timing games on Solana, and we decided to run experiments to better understand the implications. We’ve documented our findings in this research article.
Timing Games on Solana: Validator Incentives, Network Impacts, and Agave's Hidden Inefficiencies
Umberto Natale
August 13, 2025
•
18 min read
August 13, 2025
•
5 min read
TL;DR
Timing games on Solana are economically rational, providing measurable validator revenue gains:
+3.0% in total rewards (27 basis points) from combining timing games and optimization.
+1.19% (8 basis points) from timing games on fees with default MEV behaviour.
+1.4% (12 basis points) from code optimization with no timing game.
We identify four key areas of impact: (1) inflation drift due to changes in slot duration, (2) TPS behaviour under slot manipulation, (3) CU efficiency variations, and (4) downstream slot leader effects.
Slot time manipulation increases CU per block and may result in higher TPS—even with fewer slots per unit time—by enabling more efficient transaction packing.
Firedancer achieves similar efficiency without slot delays, pointing to a likely implementation inefficiency in the Agave client.
No direct evidence supports cross-slot transaction stealing under timing games, but the presence of possible structural inefficiencies in Agave warrants further investigation.
Introduction
Blockchains are built to ensure both liveness and safety by incentivizing honest participation in the consensus process. However, most known consensus implementations are not fully robust against external economic incentives. While the overall behaviour tends to align with protocol expectations, certain conditions create incentives to deviate from the intended design. These deviations often exploit inefficiencies or blind spots in the consensus rules. When such actions degrade the protocol's overall performance, the protocol design needs to be fixed, otherwise people will simply keep exploiting these weaknesses.
In a world where data is the new oil, every millisecond has value. Information is converted into tangible gains by intelligent agents, and blockchain systems are no exception. This dynamic illustrates how time can be monetized. In Proof-of-Stake (PoS) systems, where block rewards are not uniformly distributed among participants, the link between time and value can create incentives for node operators to delay block production, effectively "exchanging time for a better evaluation." This behaviour stems from rewards not being shared. A straightforward solution would be to pool rewards and redistribute them proportionally, based on stake and network performance. Such a mechanism would eliminate the incentive to delay, unless all nodes collude, as any additional gains would be diluted across the network.
In this analysis, we evaluate the cost of time on Solana from both the operator’s and the network’s perspective.
Quantifying Incentives
It wasn’t long ago—May 31st, 2024—when Anatoly Yakovenko, in a Bankless episode, argued that timing games on Solana were unfeasible due to insufficient incentives for node operators. However, our recent tests indicate that, in practice, node operators are increasingly compelled to engage in latency optimization as a strategic necessity. As more operators exploit these inefficiencies, they raise the benchmark for expected returns, offering capital allocators a clear heuristic: prioritize latency-optimized setups. This dynamic reinforces itself, gradually institutionalizing the latency race as standard practice and pressuring reluctant operators to adapt or fall behind. The result is an environment where competitive advantage is no longer defined by protocol alignment, but by one’s readiness to exploit a persistent structural inefficiency. A similar dynamic is observed on Ethereum, see e.g. The cost of artificial latency in the PBS context, but on Solana the effect may be magnified due to its high-frequency architecture and tight block production schedule.
To test this hypothesis, we artificially introduced a delay of approximately 100ms in our slot timing (giving us an average slot time of 480ms) from June 25th to July 20th. The experiment was structured in distinct phases:
June 25th to July 2nd: We employed an optimized configuration for both block fees and tips, with 480ms slot time. This phase served as a baseline to observe the global effects of timing games under optimal conditions.
July 2nd to July 10th: We deliberately degraded bundle performance to isolate and measure the impact of timing games on block fees alone, excluding the influence of tips.
July 10th to July 20th: We restored the optimized setup while continuing to apply timing games, in order to examine their combined effect.
From July 20th onward: We have operated with the optimized configuration and no timing games, serving as a post-intervention baseline.
The decision to degrade bundle performance from July 2nd to July 10th was motivated by the strong correlation between fees and tips, which made it difficult to determine whether the observed effects of delay were attributable solely to bundle processing or to overall transaction execution. Data can be checked via our Dune dashboard here.
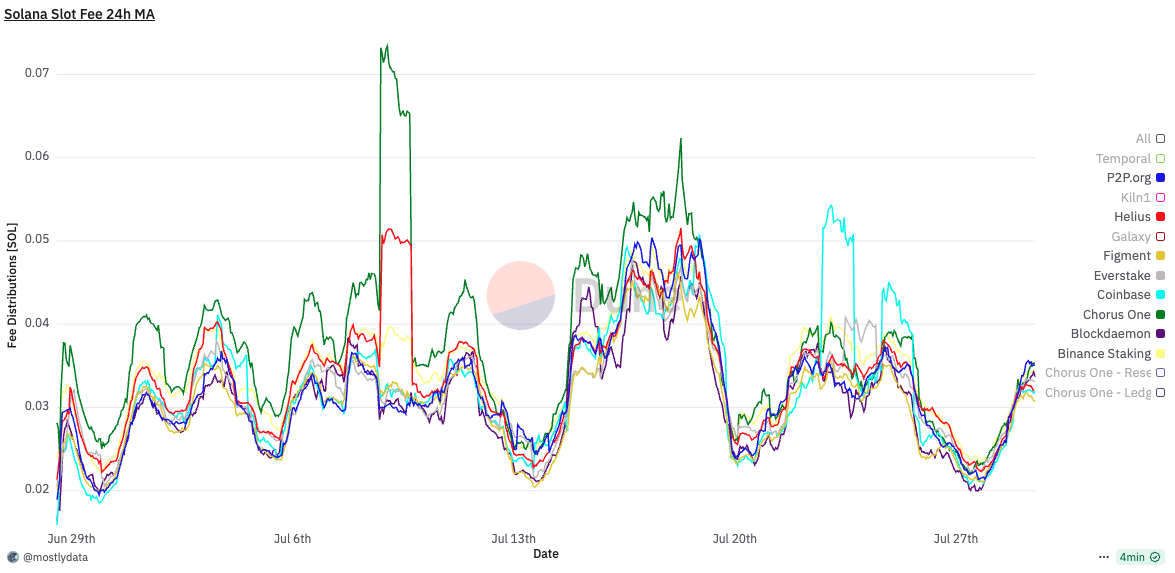
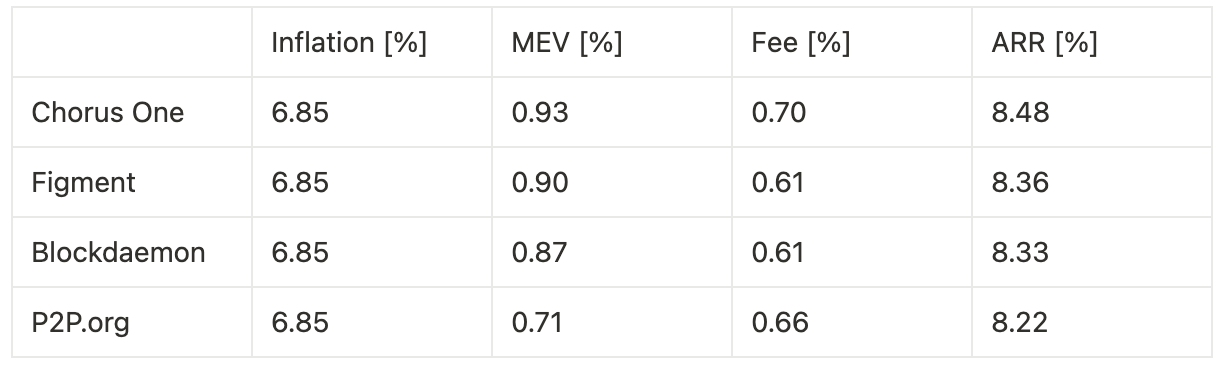
Analyzing the 24-hour moving average distribution of fees per block, we observe a consistent increase of approximately 0.005 SOL per block, regardless of bundle usage - we only observed a small relative difference compared to the case of optimized bundles. For a validator holding 0.2% of the stake, and assuming 432,000 slots per epoch, this translates to roughly 4.32 SOL per epoch, or about 790 SOL annually.
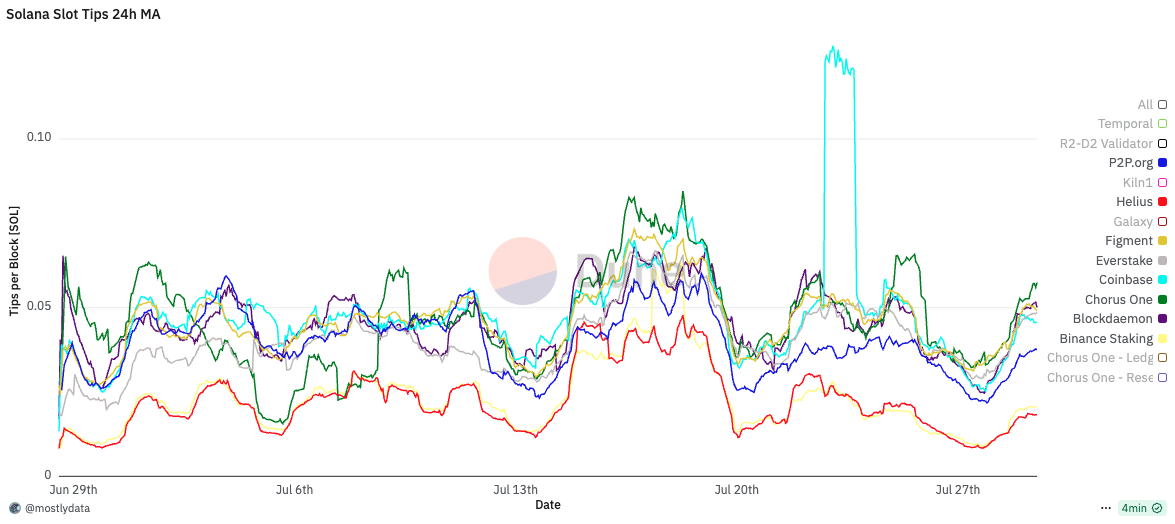
When MEV is factored in, the average fee difference per block increases by an additional 0.01 SOL. Due to the long-tailed distribution of MEV opportunities, this difference can spike up to 0.02 SOL per block, depending on market conditions. Interestingly, during periods of artificially low bundle usage, fees and tips begin to decouple, tips revert to baseline levels even under timing game conditions. This suggests that optimization alone remains a significant driver of performance.
However, as Justin Drake noted, when the ratio of ping time to block time approaches one, excessive optimization may become counterproductive. A striking example of this is Helius: despite being one of the fastest validators on Solana, it consistently ranks among the lowest in MEV rewards. This mirrors findings on Ethereum, where relays deliberately reduce optimization to preserve a few additional milliseconds for value extraction.
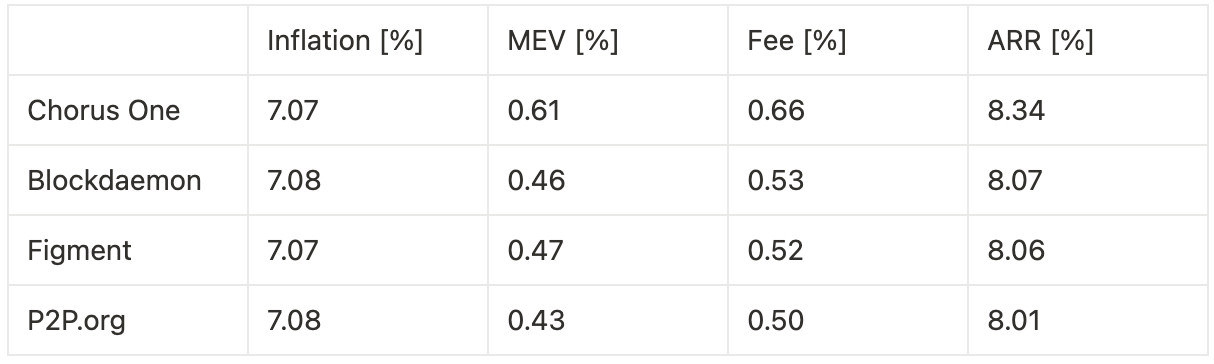
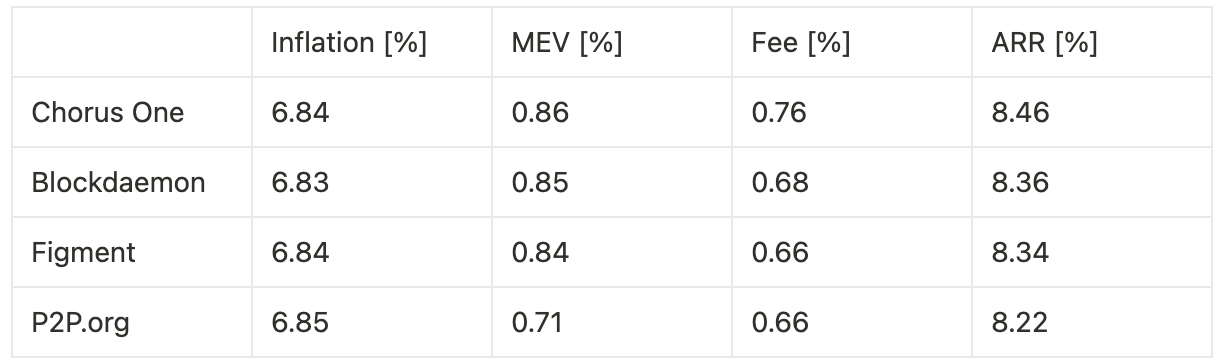
Extrapolating annualized returns across the three experimental phases—benchmarking against other institutional staking providers—we observe the following:
Timing games combined with optimization yield a 24.5% increase in fees and a 32.6% increase in MEV, resulting in an overall 3.0% uplift in total rewards, corresponding to a 27 basis point improvement in annualized return.
Timing games without bundle optimization lead to a 10.0% increase in fees, translating to an 8 basis point gain in annualized return.
Optimization without timing games produces a 3.3% increase in MEV and a 14.7% increase in fees, for a combined 1.4% boost in total rewards, or 12 basis points on annualized return.
Our analysis demonstrates that both timing games and latency optimization materially impact validator rewards on Solana. When combined, they produce the highest yield uplift—up to 3.0% in total rewards, or 27 basis points annually—primarily through increased MEV extraction and improved fee capture. However, even when used independently, both techniques deliver measurable gains. Timing games alone, without bundle optimization, still provide an 8 basis point boost, while pure optimization yields a 12 basis point increase.
These results challenge prior assumptions that the incentives on Solana are insufficient to support timing-based strategies. In practice, latency engineering and strategic delay introduce nontrivial financial advantages, creating a competitive feedback loop among operators. The stronger the economic signal, the more likely it is that latency-sensitive infrastructure becomes the norm.
Our findings point to a structural inefficiency in the protocol design. Individual actors, with rational behaviour under existing incentives, will always try to exploit these inefficiencies. We think that, the attention should be directed toward redesigning reward mechanisms—e.g., through pooling or redistribution—to neutralize these dynamics. Otherwise, the network risks entrenching latency races as a defining feature of validator competition, with long-term consequences for decentralization and fairness.
Quantifying Effects
In this section, we classify and quantify the main effects that arise from engaging in timing games. We identify four primary impact areas: (1) inflation rewards, (2) transactions per second (TPS), (3) compute unit (CU) usage per block, and (4) downstream costs imposed on the leader of subsequent slots.
Impact on Inflation
Inflation in Solana is defined annually but applied at the epoch level. The inflation mechanics involve three key components: the predefined inflation schedule, adjustments based on slot duration, and the reward distribution logic. These are implemented within the Bank struct (runtime/src/bank.rs), which converts epochs to calendar years using the slot duration as a scaling factor.
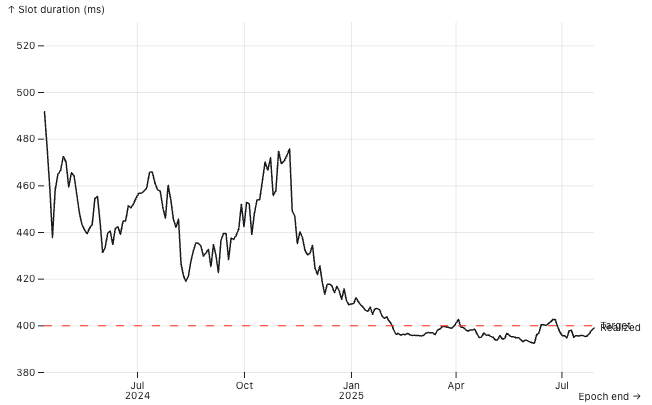
Slot duration is defined as ns_per_slot: u128 in Bank, derived from the GenesisConfig, with a default value of DEFAULT_NS_PER_SLOT = 400_000_000 (i.e., 400ms). Any deviation from this nominal value impacts real-world inflation dynamics.
The protocol computes the inflation delta per epoch using the nominal slot duration to derive the expected number of epochs per year (approximately 182.5), and thus the epoch fraction of a year (~0.00548). This delta is fixed and does not depend on the actual slot production speed. As a result, the effective annual inflation rate scales with the realized slot time: faster slots lead to more epochs per calendar year (higher total minting), while slower slots result in fewer epochs and thus reduced minting. For example:
At 390ms slot time:
Multiplier = 400 / 390 ~ 1.0256
Effective inflation = 102.56% of nominal → +2.56% real-time minting
At 500ms slot time:
Multiplier = 400 / 500 = 0.8
Effective inflation = 80% of nominal → −20% real-time minting
As shown in the corresponding plot, real slot times fluctuate around the 400ms target. However, if a sufficient share of stake adopts timing games, average slot time may systematically exceed the nominal value, thereby suppressing overall staking yields. This effect introduces a distortion in the economic design of the protocol: slower-than-target slot times reduce total inflationary rewards without explicit governance changes. While the additional revenue from MEV and fees may partially offset this decline, it typically does not compensate for the loss in staking yield.
Moreover, this creates a strategic window: node operators controlling enough stake to influence network slot timing can engage in timing games selectively—prolonging slot time just enough to capture extra fees and MEV, while keeping the average slot time close to the 400ms target to avoid noticeable inflation loss. This subtle manipulation allows them to extract value without appearing to disrupt the protocol’s economic equilibrium.
Impact on Transaction Per Second
TPS is often cited as a key performance metric for blockchains, but its interpretation is not always straightforward. It may seem intuitive that delaying slot time would reduce TPS—since fewer slots per unit time implies fewer opportunities to process transactions. However, this assumption overlooks a critical factor: longer slot durations allow more user transactions and compute units (CUs) to accumulate per block, potentially offsetting the reduction in block frequency.
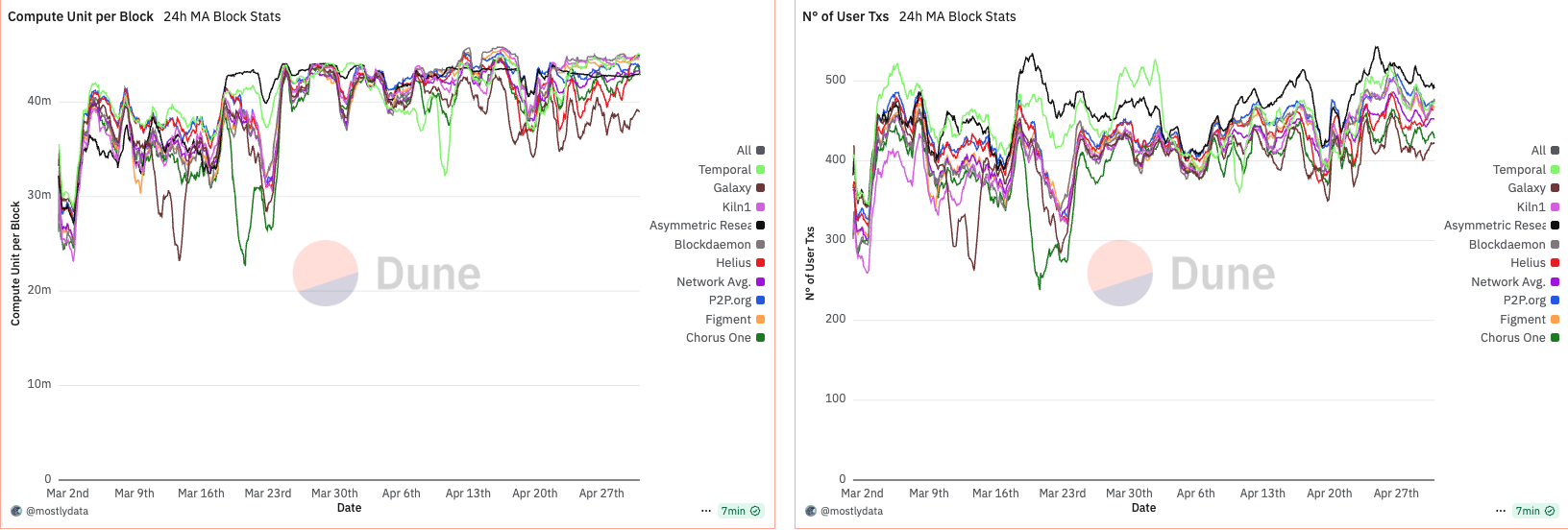
Empirical evidence from our experiment supports this nuance. During the period of artificially delayed slots (~480ms), we observed a ~100 transaction increase per block compared to other validators running the standard Agave codebase (we will address Firedancer in the next section). Specifically, our configuration averaged 550 transactions per block at 480ms slot time, while the rest of the network, operating at an average 396ms, processed ~450 transactions per block.
This results in:
Delayed slots: 550 tx/block ÷ 0.48s = 1,146 TPS
Default slots: 450 tx/block ÷ 0.396s = 1,136 TPS
Thus, despite reducing block frequency, the higher transaction volume per block actually resulted in a net increase in TPS. This illustrates a subtle but important point: TPS is not solely a function of slot time, but of how transaction throughput scales with that time.
Impact on Compute Unit
CU per block is a more nuanced metric, requiring a broader temporal lens to properly assess the combined effects of block time and network utilization.
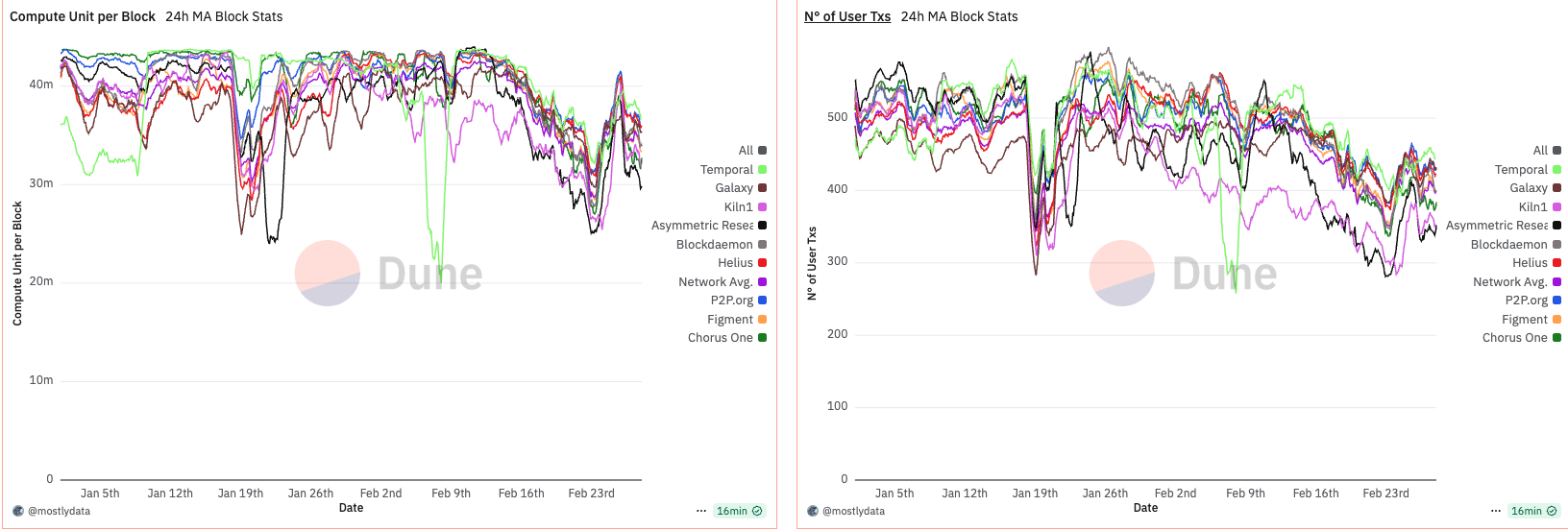
The first period of interest is January to February 2025, a phase marked by unusually high network activity driven by the meme coin season and the launch of various tokens linked to the Trump family. Notably, despite elevated traffic, we observe a dip in CU per block around January 19th, coinciding with the launch of the TRUMP token. This paradox—reduced CU per block during high demand—suggests an emerging inefficiency in block utilization.
At the time, the network-wide 24-hour moving average of CU per block remained significantly below the 48 million CU limit, with only rare exceptions. This indicates that, despite apparent congestion, blocks were not saturating compute capacity.
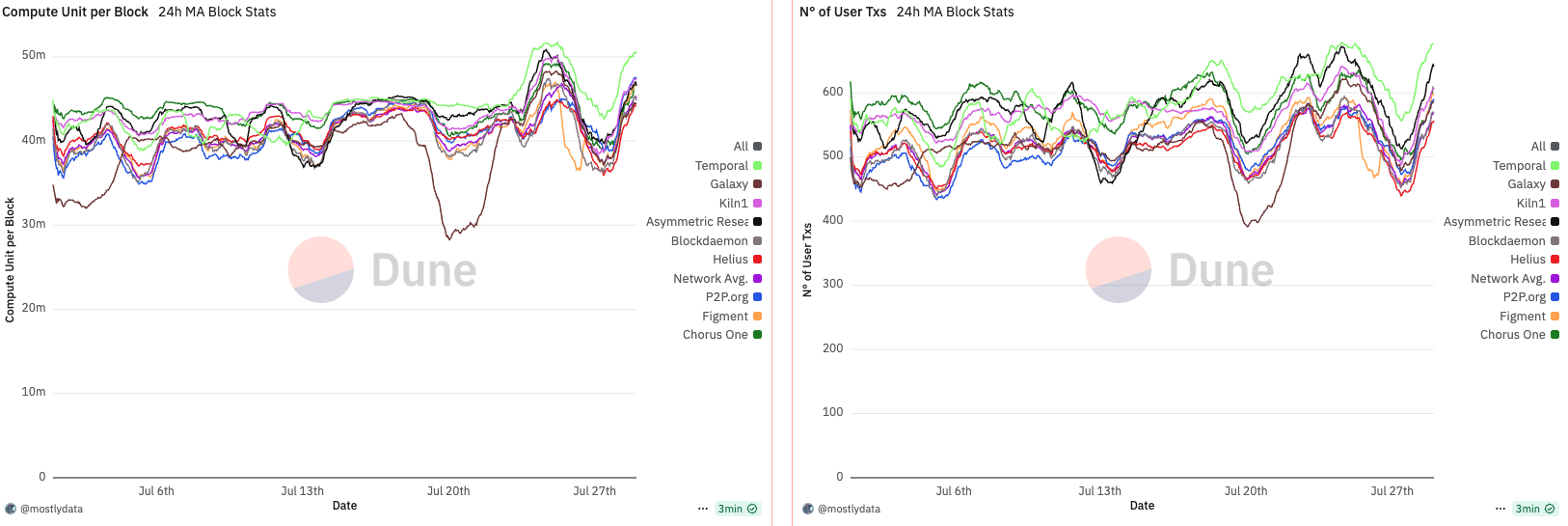
A structural shift occurred around February 13th, when approximately 88% of the network had upgraded to Agave v2.1.11. Following this, we observe a sharp and persistent drop in CU per block, implying a systemic change in block construction or scheduling behaviour post-upgrade. While several factors could be contributing—including transaction packing strategies, timing variance, and runtime-level constraints—this pattern underscores that software versioning and slot management can directly shape CU efficiency, especially under sustained demand.
Anomalous behavior in CU per block emerges when analyzing the data from March to April 2025. During this period, CU usage per block remained unusually low—oscillating between 30M and 40M CU, well below the 48M limit. This persisted until around March 15th, when a sharp increase in CU per block was observed. Not coincidentally, this date marks the point at which over 66% of the stake had upgraded to Agave v2.1.14.
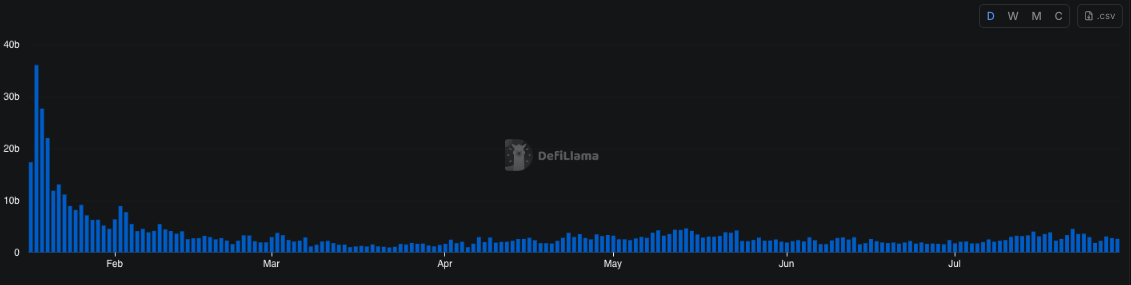
Source: DeFiLlama
What makes this shift particularly interesting is its disconnect from network demand. A comparison with DeFi activity shows virtually no change between late February and early March. In fact, DeFi volumes declined toward the end of March, while CU per block moved in the opposite direction. This suggests that the rise in CU was not driven by increased user demand, but rather by validator behaviour or runtime-level changes introduced in the upgrade.
Throughout this period, the number of user transactions remained relatively stable. Notably, Firedancer (FD)—benchmarked via Asymmetric Research as a top-performing validator—began to include more transactions per block. FD also exhibited greater stability in CU usage, implying a more consistent packing and scheduling behaviour compared to Agave-based validators.
These observations suggest that CU per block is not merely a reflection of demand, but is heavily influenced by validator software, packing logic, and runtime decisions. The sharp rise in CU post-upgrade, despite declining network activity, points to a protocol-level shift in block construction rather than any endogenous change in user behaviour.
Notably, around April 14th, we observe a widening in the spread of CU per block across validators. This timing aligns with the effective increase in the maximum CU limit from 48M to 50M, suggesting that validators responded differently to the expanded capacity. Interestingly, FD maintained a remarkably stable CU usage throughout this period, indicating consistency in block construction regardless of the network-wide shift.
What emerges during this phase is a growing divergence between early adopters of timing games and fast, low-latency validators (e.g., Chorus One and Helius). While the former began pushing closer to the new CU ceiling, leveraging additional time per slot to pack more transactions, the latter maintained tighter timing schedules, prioritizing speed and stability over maximal CU saturation.
The picture outlined so far suggests a wider client-side inefficiency, where performance-first optimization—particularly among Agave-based validators—results in suboptimal block packaging. This is clearly highlighted by Firedancer (FD) validators, which, despite not engaging in timing games, consistently approached block CU saturation, outperforming vanilla Agave nodes in terms of block utilization efficiency.
Yet, during the same period, FD validators reached comparable levels of CU saturation—without modifying slot time—simply through better execution. This reinforces the view that the observed discrepancy is not a protocol limitation, but rather a shortcoming in the current Agave implementation. In our view, this represents a critical inefficiency that should be addressed at the client level, as it introduces misaligned incentives and encourages timing manipulation as a workaround for otherwise solvable engineering gaps.
On Transaction Slot Boundaries
This brings us to the final piece of the puzzle. On Ethereum, prior research has shown that delaying slot time can enable the validator of slot N to “steal” transactions that would otherwise have been processed by the validator of slot N+1. On Solana, however, the dynamics appear fundamentally different.
While it is difficult to prove with absolute certainty that slot delayers are not aggregating transactions intended for subsequent slots, there are strong indications that this is not the mechanism at play. In our experiment, we only altered Proof of History (PoH) ticking, effectively giving the Agave scheduler more time to operate, without modifying the logic of transaction selection.
Agave’s scheduler is designed to continuously process transactions based on priority, and this core behaviour was never changed. Importantly, Firedancer's performance—achieving similar block utilization without delaying slot time—strongly suggests that the observed improvements from timing games stem from enhanced packaging efficiency, not frontrunning or cross-slot transaction capture.
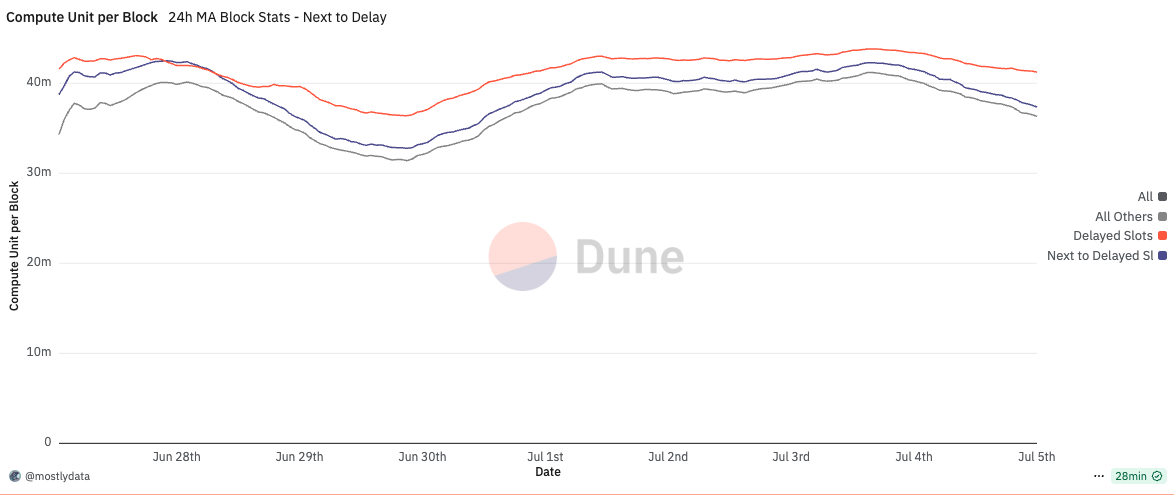
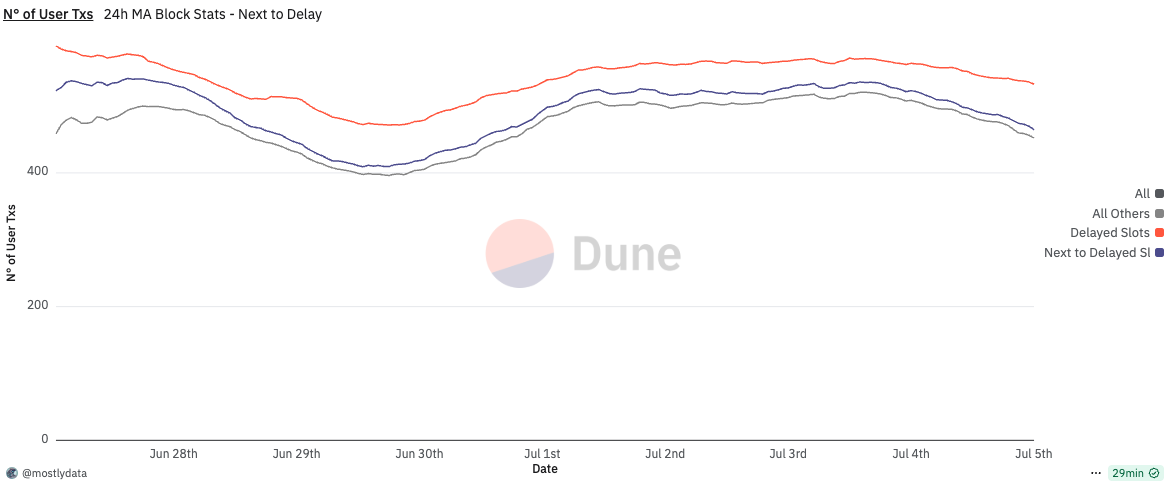
Furthermore, when we examine the number of user transactions and CU per block for slots immediately following those subject to timing games, we observe that subsequent leaders also benefit from the delayed PoH, even when running an unmodified, vanilla Agave client, cfr. here. Compared to the network-wide baseline, these leaders tend to produce blocks with higher transaction counts and CU utilization, suggesting that the slower PoH cadence indirectly improves scheduler efficiency for the next slot as well. In other words, the gains from timing games can partially spill over to the next leader, creating second-order effects even among non-participating validators.
In this light, the extended time appears to function purely as a buffer for suboptimal packing logic in the Agave client, not as a window to re-order or steal transactions. This further supports the argument that what we’re observing is not a protocol-level vulnerability, but rather an implementation-level inefficiency that can and should be addressed.
Conclusions
This document has provided a quantitative and qualitative analysis of timing games on Solana, focusing on four critical dimensions: inflation rewards, transactions per second (TPS), compute unit (CU) utilization, and costs imposed on the next leader.
We began by quantifying the incentives: timing games are not just viable—they’re profitable. Our tests show that:
Combining timing games and optimization yields a 3.0% uplift in validator rewards, or 27 basis points annually.
Timing games alone (without affecting bundle for MEV) still yield a 0.8% gain (8 basis points).
Optimization w/o Slot Delay provides a 1.4% increase (12 basis points), mainly through better CU and MEV extraction.
In the case of inflation, we showed that slot-time manipulation alters the effective mint rate: longer slots reduce inflation by decreasing epoch frequency, while shorter slots accelerate issuance. These effects accumulate over time and deviate from the intended reward schedule, impacting protocol-level economic assumptions.
For TPS, we countered the intuition that longer slots necessarily reduce throughput. In fact, because longer slots allow for higher transaction counts per block, we observed a slight increase in TPS, driven by better slot-level utilization.
The most revealing insights came from analyzing CU per block. Despite similar user demand across clients, Firedancer consistently saturated CU limits without altering slot timing. In contrast, Agave validators required delayed slots to match that efficiency. This points not to a network-level bottleneck but to a client-side inefficiency in Agave’s transaction scheduler or packing logic.
Finally, we investigated concerns around slot-boundary violations. On Ethereum, delayed blocks can allow validators to “steal” transactions from the next slot. On Solana, we found no strong evidence of this. The PoH delay only extends the scheduling window, and Agave’s priority-based scheduler remains unmodified. Firedancer’s comparable performance under standard timing supports the conclusion that the extra slot time is used purely for local block optimization, not frontrunning.
Altogether, the evidence suggests that timing games are compensating for implementation weaknesses, not exploiting protocol-level vulnerabilities. While we do not assert the presence of a critical bug, the consistent underperformance of Agave under normal conditions—and the performance parity achieved through slot-time manipulation—raises valid concerns. Before ending the analysis, it is worth mentioning that the idea of a bug, with more context around it, has been provided by the Firedancer team as well here.