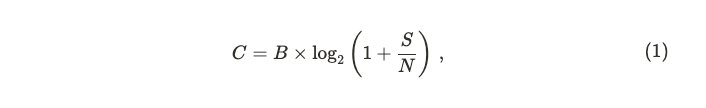Chorus One is now a part of Bitwise. Bitwise is a global, crypto-first asset manager with $11 billion+ in client assets and a diverse suite of investment solutions. Learn more about how Chorus One is growing as a part of Bitwise at onchain.bitwiseinvestments.com.
Blockchain systems face two hard limits: the speed light travels through a given medium, and Shannon Capacity Theorem. Firedancer, by Jump Crypto, re-engineers Solana validators to test these limits. In this article, we'll dive deep into the first version of Firedancer, dubbed Frankendancer, which merges a custom networking stack with Agave's runtime.
Blockchain systems like Solana face two hard limits: the speed of light traveling in a medium, slowing data transmission, and the Shannon Capacity Theorem, capping throughput even at maximum speed.
Firedancer, built by Jump Crypto, re-engineers Solana’s validator client to test these limits.
Frankendancer, the first version of Firedancer, merges a custom networking stack with Agave’s runtime.
The improvements introduced by Frankendancer include an advanced QUIC setup and a custom scheduler with different ordering logic.
Data analysis shows that Frankendancer not only includes more vote transactions per block than Agave but also handles more non-vote transactions.
Rebuilt scheduler favors conflict resolution over strict priority for better parallel execution. This reflects as more optimally packed, more valuable, blocks.
Despite a lower median priority fee, Frankendancer achieves higher throughput, hinting at superior transaction handling.
There are minor skip rates and vote latency gaps, likely due to Frankendancer’s smaller stake.
In the world of blockchain technology, where every millisecond counts, the speed of light isn’t just a scientific constant—it’s a hard limit that defines the boundaries of performance. As Kevin Bowers highlighted in his article Jump Vs. the Speed of Light, the ultimate bottleneck for globally distributed systems, like those used in trading and blockchain, is the physical constraint of how fast information can travel.
To put this into perspective, light travels at approximately 299,792 km/s in a vacuum, but in fiber optic cables (the backbone of internet communication), it slows to about 200,000 km/s due to the medium's refractive index. This might sound fast, but when you consider the distances involved in a global network, delays become significant. For example:
A round-trip signal between New York and Singapore, roughly 15,300 km apart as the crow flies (and longer via actual fiber routes), takes about 200 ms. That’s 200 ms of pure latency, before accounting for processing, queuing, or network congestion.
For applications like high-frequency trading or blockchain consensus mechanisms, this delay is simply too long. In decentralized systems, the problem worsens because nodes must exchange multiple messages to reach agreement (e.g., propagating a block and confirming it). Each round-trip adds to the latency, making the speed of light a "frustrating constraint" when near-instant coordination is the goal.
The Shannon Capacity Theorem: Another Layer of Limitation
Beyond the physical delay imposed by the speed of light, blockchain networks face an additional challenge rooted in information theory: the Shannon Capacity Theorem. This theorem defines the maximum rate at which data can be reliably transmitted over a communication channel. It’s expressed as:
where C is the channel capacity (bits per second), B is the bandwidth (in hertz), and S/N is the signal-to-noise ratio. In simpler terms, the theorem tells us that even with a perfect, lightspeed connection, there’s a ceiling on how much data a network can handle, determined by its bandwidth and the quality of the signal.
For blockchain systems, this is a critical limitation because they rely on broadcasting large volumes of transaction data to many nodes simultaneously. So, even if we could magically eliminate latency, the Shannon Capacity Theorem reminds us that the network’s ability to move data is still finite. For blockchains aiming for mass adoption—like Solana, which targets thousands of transactions per second—this dual constraint of light speed and channel capacity is a formidable hurdle.
Firedancer: A Vision for Blockchain Performance
In a computing landscape where recent technological advances have prioritized fitting more cores into a CPU rather than making them faster, and where the speed of light emerges as the ultimate bottleneck, Jump team refuses to settle for off-the-shelf solutions or the short-term fix of buying more hardware. Instead, it reimagines existing solutions to extract maximum performance from the network layer, optimizing data transmission, reducing latency, and enhancing reliability to combat the "noise" of packet loss, congestion, and global delays.
The Firedancer project is about tailoring this concept for a blockchain world where every microsecond matters, breaking the paralysis in decision-making that arises when systems have many unoptimized components.
Firedancer is a high-performance validator client developed in C for the Solana blockchain, developed by Jump Crypto, a division of Jump Trading focused on advancing blockchain technologies. Unlike traditional validator clients that rely on generic software stacks and incremental hardware upgrades, Firedancer is a ground-up reengineering of how a blockchain node operates. Its mission is to push the Solana network to the very limits of what’s physically possible, addressing the dual constraints of light speed and channel capacity head-on.
At its core, Firedancer is designed to optimize every layer of the system, from data transmission to transaction processing. It proposes a major rewrite of the three functional components of the Agave client: networking, runtime, and consensus mechanism.
Frankendancer
Firedancer is a big project, and for this reason it is being developed incrementally. The first Firedancer validator is nicknamed Frankendancer. It is Firedancer’s networking layer grafted onto the Agave runtime and consensus code. Precisely, Frankendancer has implemented the following parts:
The QUIC and UDP ingress networking pieces, using high performance kernel bypass networking.
The block distribution engine and egress networking, also using kernel bypass. The engine contains a full reimplementation of erasure coding and the Solana turbine protocol for packet routing.
Signature verification with a custom AVX512 ED25519 implementation.
The block packing logic.
All other functionality is retained by Agave, including the runtime itself which tracks account state and executes transactions.
In this article, we’ll dive into on-chain data to compare the performance of the Agave client with Frankendancer. Through data-driven analysis, we quantify if these advancements can be seen on-chain via Solana’s performance. This means that not all improvements will be visible via this analysis.
You can walk through all the data used in this analysis via our dedicated dashboard.
While signature verification and block distribution engines are difficult to track using on-chain data, studying the dynamical behaviour of transactions can provide useful information about QUIC implementation and block packing logic.
QUIC Implementation
Transactions on Solana are encoded and sent in QUIC streams into validators from clients, cfr. here. QUIC is relevant during the FetchStage, where incoming packets are batched (up to 128 per batch) and prepared for further processing. It operates at the kernel level, ensuring efficient network input handling. This makes QUIC a relevant piece of the Transaction Processing Unit (TPU) on Solana, which represents the logic of the validator responsible for block production. Improving QUIC means ultimately having control on transaction propagation. In this section we are going to compare the Agave QUIC implementation with the Frankendancer fd_quic—the C implementation of QUIC by Jump Crypto.
The first difference relies on connection management. Agave utilizes a connection cache to manage connections, implemented via the solana_connection_cache module, meaning there is a lookup mechanism for reusing or tracking existing connections. It also employs an AsyncTaskSemaphore to limit the number of asynchronous tasks (set to a maximum of 2000 tasks by default). This semaphore ensures that the system does not spawn excessive tasks, providing a basic form of concurrency control.
Frankendancer implements a more explicit and granular connection management system using a free list (state->free_conn_list) and a connection map (fd_quic_conn_map) based on connection IDs. This allows precise tracking and allocation of connection resources. It also leverages receive-side scaling and kernel bypass technologies like XDP/AF_XDP to distribute incoming traffic across CPU cores with minimal overhead, enhancing scalability and performance, cfr. here. It does not rely on semaphores for task limiting; instead, it uses a service queue (svc_queue) with scheduling logic (fd_quic_svc_schedule) to manage connection lifecycle events, indicating a more sophisticated event-driven approach.
Frankendancer also implements a stream handling pipeline. Precisely, fd_quic provides explicit stream management with functions like fd_quic_conn_new_stream() for creation, fd_quic_stream_send() for sending data, and fd_quic_tx_stream_free() for cleanup. Streams are tracked using a fd_quic_stream_map indexed by stream IDs.
Finally, for packet processing, Agave approach focuses on basic packet sending and receiving, with asynchronous methods like send_data_async() and send_data_batch_async().
Frankendancer implements detailed packet processing with specific handlers for different packet types: fd_quic_handle_v1_initial(), fd_quic_handle_v1_handshake(), fd_quic_handle_v1_retry(), and fd_quic_handle_v1_one_rtt(). These functions parse and process packets according to their QUIC protocol roles.
Differences in QUIC implementation can be seen on-chain at transactions level. Indeed, a more "sophisticated" version of QUIC means better handling of packets and ultimately more availability for optimization when sending them to the block packing logic.
Block Packing Logic
After the FetchStage and the SigVerifyStage—which verifies the cryptographic signatures of transactions to ensure they are valid and authorized—there is the Banking stage. Here verified transactions are processed.
Fig. 2: Validator TPU with a focus on Banking Stage. Source from Anza blog.
At the core of the Banking stage is the scheduler. It represents a critical component of any validator client, as it determines the order and priority of transaction processing for block producers.
Agave implements a central scheduler introduced in v2.18. Its main purpose is to loop and constantly check the incoming queue of transactions and process them as they arrive, routing them to an appropriate thread for further processing. It prioritizes transaction accordingly to
The scheduler is responsible for pulling transactions from the receiver channel, and sending them to the appropriate worker thread based on priority and conflict resolution. The scheduler maintains a view of which account locks are in-use by which threads, and is able to determine which threads a transaction can be queued on. Each worker thread will process batches of transactions, in the received order, and send a message back to the scheduler upon completion of each batch. These messages back to the scheduler allow the scheduler to update its view of the locks, and thus determine which future transactions can be scheduled, cfr. here.
Frankendancer implements its own scheduler in fd_pack. Within fd_pack, transactions are prioritized based on their reward-to-compute ratio—calculated as fees (in lamports) divided by estimated CUs—favoring those offering higher rewards per resource consumed. This prioritization happens within treaps, a blend of binary search trees and heaps, providing O(log n) access to the highest-priority transactions. Three treaps—pending (regular transactions), pending_votes (votes), and pending_bundles (bundled transactions)—segregate types, with votes balanced via reserved capacity and bundles ordered using a mathematical encoding of rewards to enforce FIFO sequencing without altering the treap’s comparison logic.
Scheduling, driven by fd_pack_schedule_next_microblock, pulls transactions from these treaps to build microblocks for banking tiles, respecting limits on CUs, bytes, and microblock counts. It ensures votes get fair representation while filling remaining space with high-priority non-votes, tracking usage via cumulative_block_cost and data_bytes_consumed.
To resolve conflicts, it uses bitsets—a container that represents a fixed-size sequence of bits—which are like quick-reference maps. Bitsets—rw_bitset (read/write) and w_bitset (write-only)—map account usage to bits, enabling O(1) intersection checks against global bitset_rw_in_use and bitset_w_in_use. Overlaps signal conflicts (e.g., write-write or read-write clashes), skipping the transaction. For heavily contested accounts (exceeding PENALTY_TREAP_THRESHOLD of 64 references), fd_pack diverts transactions to penalty treaps, delaying them until the account frees up, then promoting the best candidate back to pending upon microblock completion. A slow-path check via acct_in_use—a map of account locks per bank tile—ensures precision when bitsets flag potential issues.
Data Walkthrough
Transactions & Extracted Value
Vote fees on Solana are a vital economic element of its consensus mechanism, ensuring network security and encouraging validator participation. In Solana’s delegated Proof of Stake (dPoS) system, each active validator submits one vote transaction per slot to confirm the leader’s proposed block, with an optimal delay of one slot. Delays, however, can shift votes into subsequent slots, causing the number of vote transactions per slot to exceed the active validator count. Under the current implementation, vote transactions compete with regular transactions for Compute Unit (CU) allocation within a block, influencing resource distribution.
Fig. 3: Relevant percentiles of Vote transactions included in a block divided by software versions The percentiles are computed using hourly data. Source from our dedicated dashboard.
Data reveals that the Frankendancer client includes more vote transactions than the Agave client, resulting in greater CU allocation to votes. To evaluate this difference, a dynamic Kolmogorov-Smirnov (KS) test can be applied. This non-parametric test compares two distributions by calculating the maximum difference between their Cumulative Distribution Functions (CDFs), assessing whether they originate from the same population. Unlike parametric tests with specific distributional assumptions, the KS-test’s flexibility suits diverse datasets, making it ideal for detecting behavioral shifts in dynamic systems. The test yields a p-value, where a low value (less than 0.05) indicates a significant difference between distributions.
Fig. 4: Distribution of p-value from a dynamical KS-test computed from the usage of CU from non-vote transactions. The CDFs are computed using hourly data. Source from our dedicated dashboard.
When comparing CU usage for non-vote transactions between Agave (Version 2.1.14) and Frankendancer (Version 0.406.20113), the KS-test shows that Agave’s CDF frequently lies below Frankendancer’s (visualized as blue dots). This suggests that Agave blocks tend to allocate more CUs to non-vote transactions compared to Frankendancer. Specifically, the probability of observing a block with lower CU usage for non-votes is higher in Frankendancer relative to Agave.
Fig. 5: Relevant percentiles for non-vote transactions included in a block (top row) and fee collected by validators (bottom row) divided by software version. The percentiles are computed using hourly data. Source from our dedicated dashboard.
Interestingly, this does not correspond to a lower overall count of non-vote transactions; Frankendancer appears to outperform Agave in including non-vote transactions as well. Together, these findings imply that Frankendancer validators achieve higher rewards, driven by increased vote transaction inclusion and efficient CU utilization for non-vote transactions.
Why Frankendancer is able to process more vote transactions may be due to the fact that on Agave there is a maximum number of QUIC connections that can be established between a client (identified by IP Address and Node Pubkey) and the server, ensuring network stability. The number of streams a client can open per connection is directly tied to their stake. Higher-stake validators can open more streams, allowing them to process more transactions concurrently, cfr. here. During high network load, lower-stake validators might face throttling, potentially missing vote opportunities, while higher-stake validators, with better bandwidth, can maintain consistent voting, indirectly affecting their influence in consensus. Frankendancer doesn't seem to suffer from the same restriction.
Skip Rate and Validator Uptime
Although inclusion of vote transactions plays a relevant role in Solana consensus, there are other two metrics that are worth exploring: Skip Rate and Validator Uptime.
Skip Rate determines the availability of a validator to correctly propose a block when selected as leader. Having a high skip rate means less total rewards, mainly due to missed MEV and Priority Fee opportunities. However, missing a high number of slots also reduces total TPS, worsening final UX.
Validator Uptime impacts vote latency and consequently final staking rewards. This metric is estimated via Timely Vote Credit (TVC), which indirectly measures the distance a validator takes to land its votes. A 100% effectiveness on TVC means that validators land their votes in less than 2 slots.
Fig. 6: Skip Rate (upper panel) and TVC effectiveness (lower panel) divided by software version. Source from our dedicated dashboard.
As we can see, there are no main differences pre epoch 755. Data shows a recent elevated Skip Rate for Frankendancer and a corresponding low TVC effectiveness. However, it is worth noting that, since these metrics are based on averages, and considering a smaller stake is running Frankendancer, small fluctuations in Frankendancer performances need more time to be reabsorbed.
Scheduler Dissipation
The scheduler plays a critical role in optimizing transaction processing during block production. Its primary task is to balance transaction prioritization—based on priority fees and compute units—with conflict resolution, ensuring that transactions modifying the same account are processed without inconsistencies. The scheduler orders transactions by priority, then groups them into conflict-free batches for parallel execution by worker threads, aiming to maximize throughput while maintaining state coherence. This balancing act often results in deviations from the ideal priority order due to conflicts.
To evaluate this efficiency, we introduced a dissipation metric, D, that quantifies the distance between a transaction’s optimal position o(i)—based on priority and dependent on the scheduler— and its actual position in the block a(i), defined as
where N is the number of transactions in the considered block.
This metric reveals how well the scheduler adheres to the priority order amidst conflict constraints. A lower dissipation score indicates better alignment with the ideal order. It is clear that the dissipation D has an intrinsic factor that accounts for accounts congestion, and for the time-dependency of transactions arrival. In an ideal case, these factors should be equal for all schedulers.
Given the intrinsic nature of the dissipation, the numerical value of this estimator doesn't carry much relevance. However, when comparing the results for two types of scheduler we can gather information on which one resolves better conflicts. Indeed, a higher value of the dissipation estimator indicates a preference towards conflict resolutions rather than transaction prioritization.
Fig. 7: Relevant percentiles for the scheduler dissipation estimator divided by software version. The percentiles are computed using hourly data. Source from our dedicated dashboard.
Comparing Frankendancer and Agave schedulers highlights how dissipation is higher for Frankendancer, independently from the version. This is more clear when showing the dynamical KS test. Only for very few instances the Agave scheduler showed a higher dissipation with statistically significant evidence.
Fig. 8: Distribution of p-value from a dynamical KS-test computed from the scheduler dissipation estimator divided by software versions. The CDFs are computed using hourly data. Source from our dedicated dashboard.
If the resolution of conflicts—and then parallelization—is due to the scheduler implementation or to QUIC implementation is hard to tell from these data. Indeed, a better resolution of conflicts can be achieved also by having more transactions to select from.
Fig. 9: Relevant percentiles for transactions PF divided by software version. The percentiles are computed using hourly data. Source from our dedicated dashboard.
Finally, also by comparing the percentiles of Priority Fees for transactions we can see hints of a different conflict resolution from Frankendancer. Indeed, despite the overall number of transactions (both vote and non-vote) and extracted value being higher than Agave, the median of PF is lower.
Conclusions
In this article we provide a detailed comparison of the Agave and Frankendancer validator clients on the Solana blockchain, focusing on on-chain performance metrics to quantify their differences. Frankendancer, the initial iteration of Jump Crypto’s Firedancer project, integrates an advanced networking layer—including a high-performance QUIC implementation and kernel bypass—onto Agave’s runtime and consensus code. This hybrid approach aims to optimize transaction processing, and the data reveals its impact.
On-chain data shows Frankendancer includes more vote transactions per block than Agave, resulting in greater compute unit (CU) allocation to votes, a critical factor in Solana’s consensus mechanism. This efficiency ties to Frankendancer’s QUIC and scheduler enhancements. Its fd_quic implementation, with granular connection management and kernel bypass, processes packets more effectively than Agave’s simpler, semaphore-limited approach, enabling better transaction propagation.
The scheduler, fd_pack, prioritizes transactions by reward-to-compute ratio using treaps, contrasting Agave’s priority formula based on fees and compute requests. To quantify how well each scheduler adheres to ideal priority order amidst conflicts we developed a dissipation metric. Frankendancer’s higher dissipation, confirmed by KS-test significance, shows it prioritizes conflict resolution over strict prioritization, boosting parallel execution and throughput. This is further highlighted by Frankendancer’s median priority fees being lower.
A lower median for Priority Fees and higher extracted value indicates more efficient transaction processing. Forvalidators and delegators, this translates to increased revenue. For users, it means a better overall experience. Additionally, more votes for validators and delegators lead to higher revenues from SOL issuance, while for users, this results in a more stable consensus.
The analysis, supported by the Flipside Crypto dashboard, underscores Frankendancer’s data-driven edge in transaction processing, CU efficiency, and reward potential.